I have been heavily promoting the use of graphs per second as the preferred measure of performance, but that comes with the assumption that miners have negligible solution loss.
That is, the probability of a false negative, i.e. not finding a 42-cycle that exists in the graph, should be well under 1%.
Under that assumption, the graph rate is a good proxy for the solution rate, which is ultimately what really matters. The latter is not only harder to reliably measure but also less convenient in use as they’re often less than 0.1
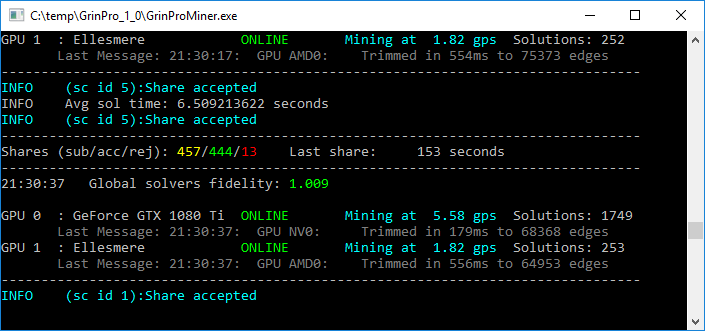
Now that many other closed source miners are popping up, and claiming significant improvements in graph rate, it’s becoming more important to know how well the assumption holds. So I propose that the miner software provides a fidelity measure, defined as
fidelity = (42-cycles_found / graphs_searched) * 42
For grin-miner, fidelity will be approximately 1.
The number of decimals shown should probably not exceed 3.
grin-miner already shows Solutions found, but not Graphs searched.
I hope to see fidelity implemented within a day or two,
and look forward to other miners copying this feature.
There actually is a tool in my cuckoo repo that can report fidelities from the solver output. In a copy of my repo, or under grin-miner/cuckoo-miner/src/cuckoo_sys/plugins/cuckoo you can try for instance
cd src/cuckaroo
make mean29x4
./mean29x4 -r 1000 -t 2 | perl …/perl/cycles.pl
2 497 0.994
4 246 0.984
6 178 1.068
8 101 0.808
10 91 0.91
12 68 0.816
14 62 0.868
16 49 0.784
18 55 0.99
20 60 1.2
22 52 1.144
24 54 1.296
26 32 0.832
28 43 1.204
30 25 0.75
32 33 1.056
34 26 0.884
36 32 1.152
38 27 1.026
40 28 1.12
42 29 1.218
and see fidelities at different cycle lengths in the last column.
feedback / suggestions for improvement are welcome…