I‘ve been working on a fast independent GPU cuckoo solver. But I work full time and I don‘t have lots of spare time now. I have working edge trimming part, but I struggle with cycle finding algorithm. I can do that on either CPU or GPU. I just need a basic concept that I can put into code, but the existing code is too hard to decode for me and I don’t want to reuse it. Anybody know any document or webpage I can use as guidance? Thanks.
Note that my cycle finding algorithm is inherently single threaded and thus better run on the CPU.
Xenoncat wrote a more complex cycle finding algorithm that does parallellize but still has negligible effect on overall performance, considering that cycle finding takes well under 1% of total runtime.
Hmm, thanks, I’ll try the whitepaper stuff - I should have thought of that one. CPU can cycle detect while GPU is doing another run so I suppose the performance hit would be near zero anyway.
It can do cucko30 down to 100k edges in about 400ms on GTX 1070. But this is a simpler version, further 30% can be shaved, but complexity doubles - this would take much more time to develop. I’ll try to finish the miner so that the output can be checked (the number of trimmed edges each round fits your miner). I’ll post more once I verify the code actually works, I found some cycles with my crappy cycle finder so it looks good so far.
Going down to 100k edges is what takes about 99% of the time, and that takes my solver 970ms on a GTX 1080Ti, a considerably faster GPU. Looks like a total speedup of around 4x!
Looking forward to your bounty claim…
I saturate the memory, core loads, caches fairly well. I don’t think it is possible to go below 300ms. 1080 are tricky, because 64B memory ops and very strange memory under-clocking on compute tasks. 1070Ti and RX Vega could be best for buck. However the enhanced complex version can be rewritten to leverage 1080Ti.
I’ll bounty the basic CUDA variant once proven and then continue with OpenCL and speed-ups.
I made some benchmarks - this is not complete trimmer, just a part of the complex one. Lower is better.
It cannot be used to improve CPU miner at all. It is all down to GPU architecture. Also it needs 8GB GPU like the stock GPU miner. It requires large amount of memory, cache and parallel processors so it remains highly resilient to ASIC.
Performance per watt is impossible to measure now because power draw is affected by voltage squared and frequency, both core and memory. And their effect on mining is not linear. In other words small performance boost is traded for large power increase.
The only complete trimmer is the basic CUDA, and I only have 1070. The numbers above are for the first trimming round + hashes. But it is only rough benchmark how things might end up.
There is two of us We finished cycle finder in C# according to the whitepaper. Verified on full cucko30 (took 200 seconds in single process). 130k edges get processed in about 70ms. Since that is less then expected best GPU solver, it will do just fine in async mode. I’ve used k0 k1 k2 k3 from your github page and both CPU and GPU agree with your solutions.
May I ask how would you actually measure the bounty speedup? De we need to recover the original nonces at this point? It is ok that both the CUDA trimmer and the manager/solver app run on windows at this point?
We would like to continue to work on a OpenCL port, Linux port, pool system and further GPU speedups after the code is made open source. Possibly with direct donations and with fair mining fee license of 1+1% (grin devs + miner devs) in the open source code. Is this compatible with the cucko GPU bounty?
I measure speedup on a range of a few dozen nonces. You will need to recover nonces, but since most graphs have no solution, this won’t affect the speed much (on average 1 in 42 graphs will have a little slowdown).
I may also run a set of specific nonces to check whether you find all solutions that my solver finds.
If your source is Windows only, then I will have to adapt your entry to Linux to be able to run and verify it myself.
And yes, of course the fair mining license is compatible with all bounties.
Ok thanks. Linux adaptation is simple (single cu file and single .cs file).
Specifically I meant do you measure the whole program from start to finish with all the allocations and initialization or if you’ll inset your own time stamps in the middle? In other words what does your program actually measure when it prints solution time?
Assuming you don’t overlook solutions (or at most a negligible fraction), what matters is the graphs per second throughput. Allocations and initialization don’t affect throughput and should not be counted, or at least amortized over a great many nonces.
You may assume something like
time ./cuda30 -r 100
used for measurement.
Makes sense. I do lose small percentage of edges in the first round, but that is SW implementation issue caused by architecture of HW and can be fully resolved. Ultimately it runs little faster but with a tiny chance of missing a solution. I’ll let you know once the project is uploaded to github. Thanks for your help.
Two issues remain. First, minimize edge losses (few %) in the beginning and second: figure out how to make it more Linux compatible for the bounty. I use some specific stuff to transfer trimmed edges to the master process that makes the it fast. I’ll have to find another way for linux.
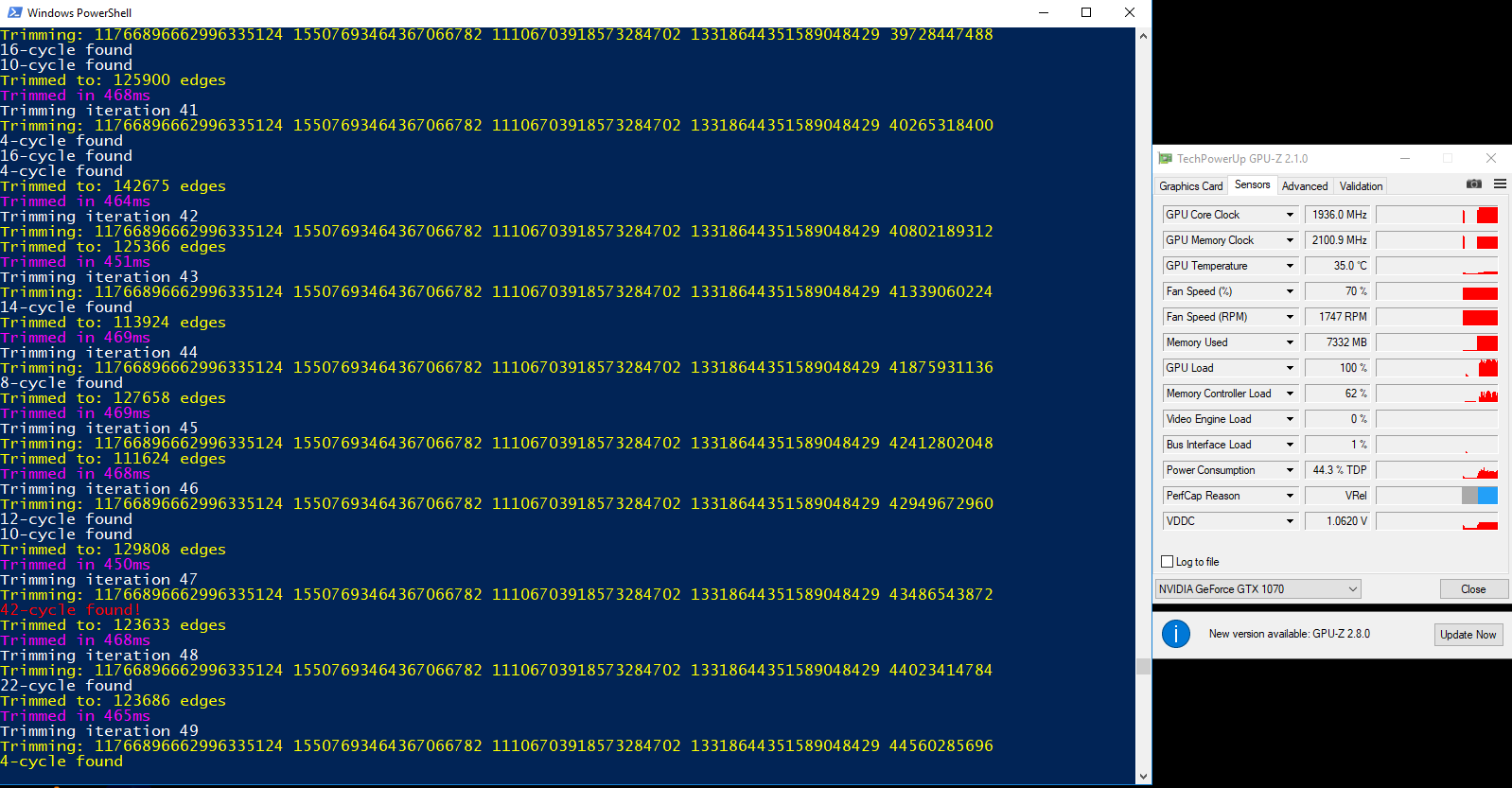
Your screen shot leaves me with some questions:
Are the different iterations for different nonces?
The timings and cycles make me think they are.
But then what are the lines with 4 long numbers and 5th shorter number?
Losing even 1% of edges is quite severe. You want to get down below 0.1% to have small effect on solution rate.
For transfer of trimmed edges, don’t you use cudaMemcpy to transfer from device to host?
4 long numbers are header constants, the shorter number is starting nonce that gets incremented each time. Basically inputs for the siphash function of the first edge. This is just for testing. Cycles are detected during next trimming so GPU is trimming non-stop. The header hashes are from https://github.com/tromp/cuckoo/blob/master/GPU.md - but I did not print them as hex.
I’ve observed that solutions get lost sometimes, but I’ll implement fixes that will make it a non-issue.
I do collect all edges at the end and use single cudaMemcpy to host, however then I use memory mapped file from WinAPI to get it out of C++ side. Boost has both sockets and mapped files so I’ll use that. I’m not C++ expert, but I’ll manage.
It will compile in dotnet core or mono, so apart from that it is completely multi-platform.
 We finished cycle finder in C# according to the whitepaper. Verified on full cucko30 (took 200 seconds in single process). 130k edges get processed in about 70ms. Since that is less then expected best GPU solver, it will do just fine in async mode. I’ve used k0 k1 k2 k3 from your github page and both CPU and GPU agree with your solutions.
We finished cycle finder in C# according to the whitepaper. Verified on full cucko30 (took 200 seconds in single process). 130k edges get processed in about 70ms. Since that is less then expected best GPU solver, it will do just fine in async mode. I’ve used k0 k1 k2 k3 from your github page and both CPU and GPU agree with your solutions.