you may have already noticed the new Mozkomor miner (the bounty claim repo is called GrinGoldMiner). The algorithm is cut down to bare bones to eliminate any bugs and to mine properly without issues. There are many possible improvements both general and for specific GPUs like 1080Ti.
We can’t dedicate large amount of time to it and so it is unlikely that this miner will be fastest on mainnet and used by anybody. The modified fair mining licence is therefore mostly academic topic, we just try to set a good example.
So the question is, what is the best way to help grin now? OpenCL port to show it can work on all HW? Connect it to grin plugin over TCP (LAN) so that one can run a node in, say VM, like us, and mine elsewhere? Focus on raw speed so it has a chance to beat closed miners? Multiple GPU support? Other?
Impressive results with your edge trimmer! Many people have asked recently about mining on AMD cards and what the most efficient Grin mining rig would look like, so IMO an OpenCL miner would be a great thing to have first!
About TCP, last week we got PR submission to integrate stratum interface for the miner plugin, so people are already working on that. You could find more info in the dev channel on gitter.
Update: OpenCL version is partly finished. Now faster on nvidia by about 25%. AMD hardware appears to be reasonably competitive if Siphash-1-3 is used instead of Siphash-2-4. AMD Vegas will not rule as in monero, performance of cards might be closer to what we see in modern games. Older RX 480 and RX 580 will not stand out as it is with ethereum (I don’t have any now, just a guess).
While ASIC can still do siphash cheaply, it would still need expensive GPU-like structure to move edges around quickly. When trimming, my 1080 Ti draws full power (250W) while actively using over 20MB of SRAM, over 5GB of DRAM and has over 50 000 threads in flight to hide latency. I’d say that is really good. While it is fast, it saps lots of power so small devices are not completely out of the game when it comes to performance per watt. And it is not likely that a hidden player will have something twice as effective unless a new algorithm is found.
The most memory saving algorithm needs to move around roughly 20GB of data for each graph solution (computing endpoints on the fly, as suggested by John Tromp). So purely from memory perspective, 2 gps is possible on PC like dual channel DDR4 and 20 gps on top end GPU like memory @512GB/s. Assuming 100% memory utilization and lots of SRAM buffers + (asic/hash) cores to hide DDRXY burst access latency.
1080 Ti - 5.2 gps @ 250W
1080 Ti - 4.0 gps @ 125W (over 50% could be memory power + controller)
i7 ~ 0.5 gps @ 50W
Best mining HW could be next gen nvidia with 16gbps GDDR6 memory. Most power efficient could be something with HBM2 that draws only approx. 30W for 16GB+controller.
Update 2: AMD Vega matches 1080 Ti at low power early in the algorithm (the most difficult part), but gets completely thrashed by nvidia as rounds get progressively thinner. There are multiple ways how to adapt the algorithm to prevent stalling on AMD, but I need to explore them. Having Vega64 2-3x slower is not acceptable.
Update 3: Tested stratum connectivity to Grin node with Urza. Seems to work. Got a helpful tip from OhGodACompany about a strange AMD HW feature that causes the performance drop on AMD. Unfortunately it means I need to rewrite the already verified AMD code, again, and OpenCL version will be pushed back a bit.
Will have to postpone efficient AMD code after testnet3. While I learned a lot so far, the Vega64 I have for testing is tricky and I already failed few times to place it ahead of 1070. I have designed the final algorithm, but only on paper and now I lack willpower and time to finish it. I’ll probably release the slow AMD version for testnet3 alongside other planned miner usability and reliability updates.
A little thought about theoretical max. speed of cuckoo cycle. Speculation ahead.
GTX 1080 Ti = 7 gps @ 250W 1000$ (likely top optimization limit)
a box with 5x asic+hbm = 150 gps @ 250W X000$ (speculation on power)
It gets more little bit more funny with lean miner 30 and a single chip with size similar to 1080 Ti die. I initially thought that it was still latency limited. But one can simply feed an edge into the pipeline every clock cycle, the question is how many parallel pipelines can the SRAM handle to service. I would think that with more parallel engines, latency would gradually increase, but latency is hidden with millions of edges entering the pipeline. I’m little concerned about it. I’ve noticed a possible switch to cuckoo31, the gpu algorithms don’t have major issues with bumping up the size (8 GB GPU only), if it comes to that, out of the blue.
I was thinking about algorithms that would solve cuckoo33 on 8-16GB GPUs and what would be the penalty compared to, say, an asic. I like to picture the worst case scenario first and I don’t like what I see. I would actually like to be wrong this time and I would not mind if somebody calls bs on this one.
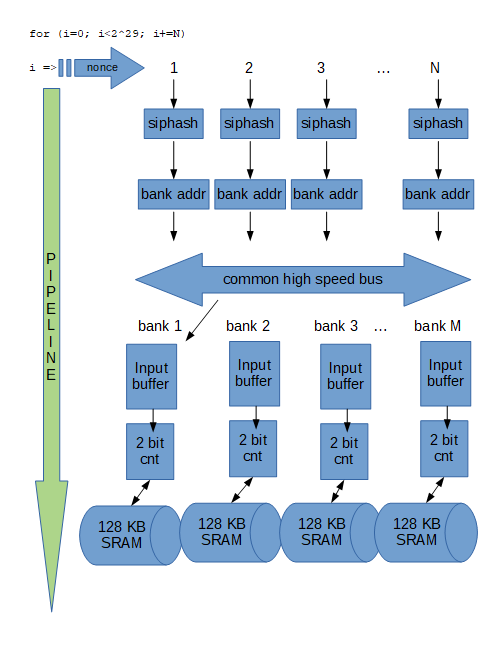
Let’s say we have a single chip asic with 128MB(+64MB) of SRAM. Let’s consider first half of first trimming round (for simplicity). We build 128 parallel pipelines for edges. As we increment current index (nonce) we feed it to those 128 pipelines each clock cycle (see picture). Siphash could have 7 stages, the whole pipeline from start to final memory increment could be, say, 30 stages. That means there are 30 edges in each pipeline at any given time, but we still process one edge every clock cycle in each of the 128 pipelines.
So we need 4 million clock cycles to finish first stage (2^29 / 128) and another 4 million for second pass. At 1 Ghz that is 8/1000 s => 8ms. Now we are in ballpark numbers so say this is an order of magnitude faster compared to 1080 Ti and possibly an order of magnitude less power. We just made 100x more efficient solver.
But why stop at 128 pipelines? Where is the limit? Each time this number is doubled, speed doubles, possibly with just a fraction more total transistors. I’m not sure how to define upper limit on this or similar design. The interconnect in the middle could be a bottleneck, every wasted cycle there and at the 2bit counters means dramatic slow-down.
Shared memory on GPU works like this. There are 32 banks servicing total of 96KB of SRAM and each of the 128 processors can access any address. Bank conflicts are serialized - input buffer in the image above.
Cuckoo33 miner could work with 128MB counter memory, but it would have to do 8 passes, eating 8x more energy and 64x more work compared to cuckoo30, but saving manufacturing cost.
One might limit this design by making each pipeline more complex and throw in some multiplications, but I’m not sure about that.
If you double the number of memory banks you double the bandwidth. It is not a limit, it is the final property. Same with latency.
What do you mean by more work? Where does 64x come from?
You can simply increase counters only of 1/8 edges (based on a mask), second pass makes them alive/dead. Repeat for next 1/8 th of edges. By 1/8 I mean you only care about edges that end with 000, then 001, 010, … The DRAM bit-field still needs to hold all edge bits.
8x bigger cuckoo × 8 passes = 64, the number was just for clarity, it is not relevant
If you double the number of memory banks you double the bandwidth.
You also double contention on the common high speed bus. At some point you’ll need to change from a shared bus to some network topology.
An alternative answer to your question is: the limit is the cost and power consumption of SRAM.
You can simply increase counters only of 1/8 edges
Ah, overlooked the fact that you’re not increasing counter memory.
Yes, the time/memory trade-off for counters is that with 2^k fewer counters you need to read the edge bitmap and compute siphashes 2^k as many times.
In lean_miner this k is the preprocessor symbol PART_BITS.
Total SRAM size is constant (the image shows 128KB only for clarity). Additional banks only divide the SRAM transistors into smaller and smaller groups. Latency of the common interconnect is not important as the design is fire and forget. It can be 20 stages of convoluted topology, but as long as the 20 stage design gets the edge to its bank in 40 or so cycles, it’s fine. I think the common interconnect design is the limit, but we don’t know what it actually is. It can be as fast as a GPU or 300x faster.
I guess the reason for the post was that I was unhappy with my speed estimate. If 32 bank GPU shared memory has 4 cycles latency and there are 2048 total banks across all of the CUs, it would seem possible to build more stages on top of them (say one extra for each doubling) to make them work as one. But that is only a though experiment, this is above my pay grade.
It is my personal opinion that single chip like this can be constructed and with at least 500x advantage would render cpu/gpu mining (of current cuckoo30) dead on arrival. I’m not a big fan of “hoping” for the best.
We start with running on foot (CPU?). Then people eventually start showing up to the race with bicycles (GPU?). Then we have faster contraptions eventually come to the race, people with their motorcycles, automobiles, rocket propelled vehicles, and flying broomsticks?
So we’re saying we want to keep this strictly a foot race? Or at least, some magic spell that makes bicycles just as slow as running… and a bad fortune spell that at least makes it super-duper expensive / technically infeasible (as the market /costs / tech level currently stands) for anything FPGA-ish or ASIC-ish?
Given your post, albeit theory, I think does warrant some serious consideration.
The potential danger is that people will line-up for the race with their bikes only to be left in the dust by broom-stickers in the first 100 meters. There is a lot of magic in making a good broomstick and rewards for winning are so sweet it may not be for public sale initially.
There were some ideas in the other thread so that you would be required to drink a beer every half-mile before allowed to continue in the race. And since there is only so much alcohol and water you can drink per unit of time, it evens the chances (unless you are Irish and ride a sheep).
But it is more costly to organize such race, more difficult to verify the person did not just vomit it all into the first bush etc. I would not call cuckoo race broken, it is well designed for simple competitive racing.
Hello,
I am trying to test this mozkomor’s GrinGoldMiner(Testnet3 cuda Win64 1.1 , also tried benchmark only version) under Win10.
I have drivers 398.36, dotnet core 2.0, and VS2017 C++ runtime installed…, but got this error when try to test it:
dotnet Theta.dll -d 0 1 2 3 -a 167.99.228.15:13416
Connecting to : 167.99.228.15
Connected to node.
Waiting for next block, this may take a bit..........
TCP IN: {"id":"Stratum","jsonrpc":"2.0","method":"job","params":{"difficulty":1,"height":19634,"pre_pow":"00010000000000004cb2a5c42bb8a350debc0bab50c54df51a03d8a046f8f56c814ea40dbc31b2c2df68000000005b559df20000000000416e35c758c675638b453efbd0c4a806a8694616dc3ec1198b1bab113422317b097bcf111809c6d9695967946afd503e5c95fe258dd06a21afd97e1d5f68aad8b9e33bd011ae0ea77d31f31e7400b42de076e4290d11adb356308a2324bf467c77348dfba854c0f21cd5c9b273de4368978cd9a91c1fbb14d7c7060827b196221c65f709ec4fbc85277619864a961153a98ad61fa2a59c29a2f470a20fce7e0a03419ec9000000000000deae000000000000bc21"}}
Starting CUDA solver process on device 0
C++ trimmer not in ready state!
Console output redirection failed! Lets try to use sockets for OpenCL miner instead...
CUDA launch error
Finished in 11251ms
Is it driver related problem? 'cos nvidia drivers 398.36 are CUDA 9.2