I have been doing some thinking/reading around “UTXO Obsolescence” and something has been bothering me. We would need a Merkle Proof for every output being spent this way. And these get expensive relative to simply referencing an output via its commitment.
It would be great if we could aggregate Merkle proofs somehow. But I have not seen anything in the literature about aggregating Merkle proofs, how to go about doing it, or if it is even possible to aggregate multiple proofs.
I think it is possible to aggregate Merkle proofs where the aggregate proof is smaller than simply combining multiple proofs.
So I’m wondering a couple of things -
- Where is the flaw in my reasoning here?
- And in the unlikely event this does actually work - has this been described anywhere before?
Merkle Proofs
A Merkle proof gives us a way of proving that an element exists in a Merkle tree.
It does this by providing a list of hashes, such that we can reconstruct the path from the element up to the root and derive a matching root hash.
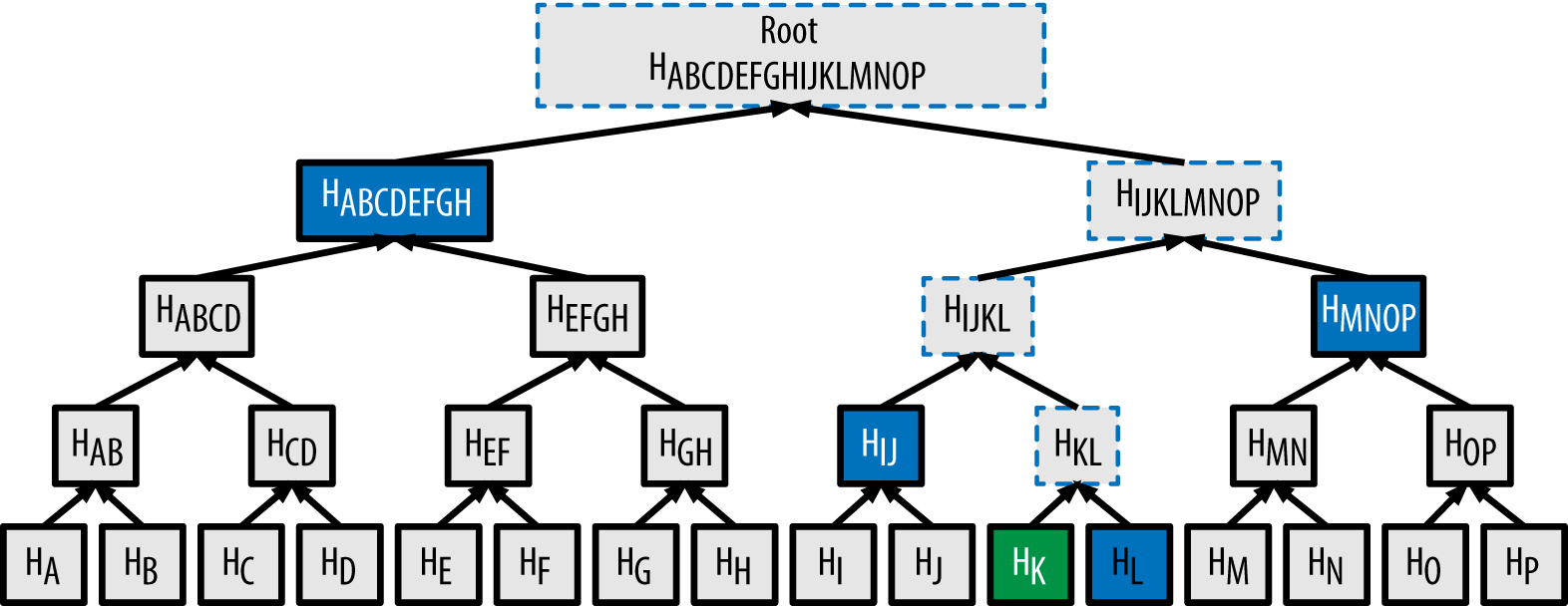
In the example above we can prove K exists in the Merkle tree via Hk and the “sibling” hashes [HL, HIJ, HMNOP, HABCDEFGH]. By hashing these siblings together we can derive the path from HK up to the root and confirm the root matches that of our Merkle tree.
If we can do this for HK we know both that the value K was correct and that it exists at the specified leaf position.
We can also build a separate Merkle proof for a different leaf position, say HA.
This proof would contain the following sibling hashes - [HB, HCD, HEFGH, HIJKLMNOP].
Aggregate Merkle Proofs
So the question is can we aggregate these two Merkle proofs, to prove that both HA and HK are elements in the Merkle tree?
HA, Proof: [HB, HCD, HEFGH, HIJKLMNOP]
HK, Proof: [HL, HIJ, HMNOP, HABCDEFGH]
At first glance it appears unlikely because there is nothing obviously in common between these two proofs.
But on closer inspection - the pair (HABCDEFGH, HIJKLMNOP) are the two children of the root node. If we know both of these we can derive the root (as we do for a single Merkle proof).
We can derive HABCDEFGH by following the Merkle proof path up from HK.
Likewise we can derive HIJKLMNOP from the Merkle proof for HA.
So with appropriate handling of the derived hashes below the root I think we can represent this aggregate proof in a more compact way (simply omitting any pairs of child hashes that can be derived by the proofs themselves) -
HA, Proof: [HB, HCD, HEFGH]
HK, Proof: [HL, HIJ, HMNOP]
Given this set of sibling hashes we can still derive the root hash and verify it matches.
Q) Does this compact representation of an aggregate Merkle proof reduce the security of the proof(s)?
Can we prove that all leaf nodes beneath a given parent node are in a Merkle tree? And what would this aggregate proof look like?
i.e. Can we prove that [A, B, C, D, E, F, G, H] are all in the Merkle tree?
We would need [HA, HB, HC, HD, HE, HF, HG, HH] and from these we could derive HABCDEFGH. We would then only need the additional sibling hash HIJKLMNOP to verify the root hash was indeed correct.
[HA, HB, HC, HD, HE, HF, HG, HH], Proof: HIJKLMNOP
The aggregate proof here is simply the list of sibling hashes above the derived root of all the provided leaf positions. In this case simply a single hash one level beneath the root.
By proving HABCDEFGH is the sibling of HIJKLMNOP beneath the root we prove for all the leaves beneath HABCDEFGH.
This is significantly smaller than requiring a full Merkle proof for each leaf node.
Intuitively it seem to make sense - if we have all the leaves beneath a parent position we can prove that rehashing all the leaves will produce a matching parent hash.
If we had all the leaves in the full Merkle tree we would not need any additional Merkle proof data to verify that they were indeed the full set of leaf nodes in the tree. We could simply rebuild the full tree and inspect the root hash.
-
This appears to imply these aggregate proofs get more efficient, the more leaf nodes we are proving (which seems like a desirable property).
-
This also suggests these proofs can be aggregated in a non-interactive way. You don’t need to know anything about the Merkle tree or the proofs being aggregated beyond being able to identify pairs of siblings to remove.
And I don’t see how this would necessarily reduce the security of the proofs. If I can rebuild the tree and produce the same root (given a set of nodes at fixed leaf positions and a fixed Merkle tree size) then it would appear sufficient to prove all the leaves are actually leaves of said tree.
Is there a flaw here? And if this does work has it been described previously somewhere?
I cannot find anything in the literature that touches on this.